我在哪?
我是谁?
我在哪?
我是谁?
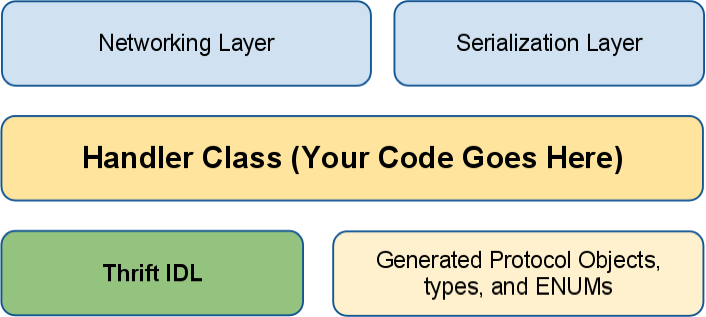
Thrift: Apache基金会下的软件栈,提供了根据IDL进行RPC的PRC工具。
Thrift中的IDL。
# Simple Calculator Service
typedef i32 int
enum Operators {
ADD = 0,
SUB = 1,
MUL = 2,
DIV = 3
}
struct Expression {
1: i32 a = 0,
2: i32 b,
3: Operators op
}
exception InvalidOperation {
1: i32 code,
2: string msg
}
service SimpleService {
string ping(1:string msg),
i32 cal(1:Expression exp) throws (
1: InvalidOperation exc
)
}
class SimpleHandler:
def ping(self, msg):
print("Get Ping")
return "Pong %s" % msg
def cal(self, exp):
print("Get Cal")
ops = dict(zip([0,1,2,3], [operator.add, operator.sub, operator.mul, operator.floordiv]))
if exp.op == 3 and exp.b == 0:
raise InvalidOperation(233, 'div 0 error')
return ops[exp.op](exp.a, exp.b)
if __name__ == '__main__':
handler = SimpleHandler()
processor = SimpleService.Processor(handler)
transport = TSocket.TServerSocket(port=9090)
tfactory = TTransport.TBufferedTransportFactory()
pfactory = TBinaryProtocol.TBinaryProtocolFactory()
server = TServer.TSimpleServer(processor, transport, tfactory, pfactory)
server.serve()
transport = TSocket.TSocket('localhost', 9090)
transport = TTransport.TBufferedTransport(transport)
protocol = TBinaryProtocol.TBinaryProtocol(transport)
client = SimpleService.Client(protocol)
transport.open()
print(client.ping("Hi From Client"))
print(client.ping("Hi Again From Client"))
exp = Expression()
exp.a = 10
exp.b = 20
exp.op = Operators.ADD
print(client.cal(exp))
exp.b = 0
exp.op = Operators.DIV
print(client.cal(exp))
transport.close()

为什么链路分析很重要?
C10K问题在1999年被提出,随着技术的发展,又出现了C100K,C10M等等相近的问题,不过问题本质相同。
这个问题的本质在于如何优化网络套接字,从而让服务器可同时处理大量的客户端请求。
并发连接和每秒请求数(QPS)不同。QPS可以通过提高处理速度(吞吐量)来提高。而并发连接数则要靠对于资源调度来实现。
既每个请求使用一个线程。
这种处理方式主要有两个问题。
lea
linux的thread stack size是8MB(ulimit -s),那么512个thread就可以撑爆一个32位主机的内存。这个问题在64位主机上的影响不大,但是处理10k请求就需要80GB内存,这还是有些可怕的。
排开内存问题外,更大的问题是上下文切换时带来的开销,这里我不太懂,可以参考这篇Article,讲的很详细。
也就是下面所说。
Select和Epoll在大体上相同,在有些小细节上有些不同。
先看一下 man select 的用法
int
select(int nfds, fd_set *restrict readfds, fd_set *restrict writefds, fd_set *restrict errorfds,
struct timeval *restrict timeout);
readfds, writefds和errorfds。所以你在跑主循环的时候必须要备份这些变量,否则select就会占用这些字节。Poll不会改变输入的任何数据,所以同一组输入可以一直拿来用。FD_SETSIZE才行。两个速度基本相同,都很慢(大佬说的)。
nfds,表明最多检查多少个FD,poll去掉了这个参数。这是tornado源码分析的第一部分,主要讲ioloop的相关实现。
直接看源码往往会让人无从入手,我们最简单的例子开始。
import tornado
import tornado.ioloop
import tornado.web
class SimpleHandler(tornado.web.RequestHandler):
def get(self):
self.write("Test")
if __name__ == "__main__":
app = tornado.web.Application([
('/', SimpleHandler)
])
app.listen(2333)
tornado.ioloop.IOLoop.current().start()
从这个简单的例子里,我们干了这几件事:
HandlerHandler实例化了一个ApplicationApplication监听端口。ioloop其中最重要的就是IOLoop,tornado所有的膜法基本都集中在这个类中。
初见IOLoop这个类我是很懵逼的,Epoll呢?Select呢?除了current这个用来获取单例的静态方法外,start和其他一些Handler相关的方法都是NotImplemented,下面的instance函数也只是做了一下单例检查。
@staticmethod
def instance():
"""Returns a global `IOLoop` instance.
Most applications have a single, global `IOLoop` running on the
main thread. Use this method to get this instance from
another thread. In most other cases, it is better to use `current()`
to get the current thread's `IOLoop`.
"""
if not hasattr(IOLoop, "_instance"):
with IOLoop._instance_lock:
if not hasattr(IOLoop, "_instance"):
# New instance after double check
IOLoop._instance = IOLoop()
return IOLoop._instance
子类看不出门道,那就回到父类看。
在Configurable这个类中,我们发现__new__方法被改写了,实例的创建逻辑被修改。
def __new__(cls, *args, **kwargs):
base = cls.configurable_base()
init_kwargs = {}
if cls is base:
impl = cls.configured_class()
if base.__impl_kwargs:
init_kwargs.update(base.__impl_kwargs)
else:
impl = cls
init_kwargs.update(kwargs)
instance = super(Configurable, cls).__new__(impl)
# initialize vs __init__ chosen for compatibility with AsyncHTTPClient
# singleton magic. If we get rid of that we can switch to __init__
# here too.
instance.initialize(*args, **init_kwargs)
return instance
在IOLoop创建实例时创建出的实际是IOLoop.configured_class(),而在configured_class中,又取了IOLoop的configurable_default。
# IOLoop.configurable_default
@classmethod
def configurable_default(cls):
if hasattr(select, "epoll"):
from tornado.platform.epoll import EPollIOLoop
return EPollIOLoop
if hasattr(select, "kqueue"):
# Python 2.6+ on BSD or Mac
from tornado.platform.kqueue import KQueueIOLoop
return KQueueIOLoop
from tornado.platform.select import SelectIOLoop
return SelectIOLoop
可以看到,在configurable_default中,tornado按照平台差异,取了不同的异步实现方式。IOLoop实际创建的实例其实也是这几个之中的一个。
以Linux为例,看一下EPollIOLoop的实现,
class EPollIOLoop(PollIOLoop):
def initialize(self, **kwargs):
super(EPollIOLoop, self).initialize(impl=select.epoll(), **kwargs)
其中EPollIOLoop只修改了PollIOLoop中initialize的参数,实际逻辑在PollIOLoop中。
OK, 到这里,我们整理一下。
current创建/获取了一个IOLoop对象。IOLoop重写了__new__方法,从而使实际构建的实例是平台相关的。PollIOLoop的初始化参数。绕了一大圈,总算找到了实际的实现逻辑。
大致过了一遍这个类,是否觉得豁然开朗?不管是add_handler、update_handler,remove_handler这几个事件相关的函数,还是start这个入口函数,都在这里面实现了。
从这几个事件注册相关的函数开始,我们看看tornado的魔法究竟是如何实现的。
def add_handler(self, fd, handler, events):
fd, obj = self.split_fd(fd)
self._handlers[fd] = (obj, stack_context.wrap(handler))
self._impl.register(fd, events | self.ERROR)
add_handler中,tornado将文件对象与文件描述符(fd)分开,建立了fd到handler之间的映射,并且在_impl(此处是select.epoll())建注册了fd上的事件,update_handler和remove_handler做的也是如其名的功能,不再赘述。
The Golden Key
整个程序的主循环。
start中前半部分都在处理timeout和Waker相关的逻辑,在这里还没有直接遇到,先跳过。
直接看While True里面的东西。
try:
event_pairs = self._impl.poll(poll_timeout)
except Exception as e:
# Depending on python version and IOLoop implementation,
# different exception types may be thrown and there are
# two ways EINTR might be signaled:
# * e.errno == errno.EINTR
# * e.args is like (errno.EINTR, 'Interrupted system call')
if errno_from_exception(e) == errno.EINTR:
continue
else:
raise
可以看到,主循环中通过poll方法得到最新的事件,通过事件对应的fd得到相应的handler,再用handler处理这个事件。
整个事件循环的流程大致如下。
add_handler -> poll event -> handle event
至此,整个torando的ioloop已经较为清晰的展现在我们面前,但是Application等相关handler如何被注入到这个ioloop中的,这些会在之后的笔记中写出。
用epoll写一个简单的返回helloworld的非阻塞异步http服务器。
import select
import socket
response = b'HTTP/1.0 200 OK\r\nDate: Mon, 1 Jan 1996 01:01:01 GMT\r\n'
response += b'Content-Type: text/plain\r\nContent-Length: 13\r\n\r\n'
response += b'Hello, world!'
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
server.bind(('0.0.0.0', 8080))
server.listen(1)
server.setblocking(0)
event_imp = select.epoll()
event_imp.register(server.fileno(), select.EPOLLIN)
try:
connections = {}
requests = {}
responses = {}
while True:
event_pair = event_imp.poll(1)
for fileno, event in event_pair:
if fileno == server.fileno():
connection, address = server.accept()
connection.setblocking(0)
event_imp.register(connection.fileno(), select.EPOLLIN)
connections[connection.fileno()] = connection
requests[connection.fileno()] = b''
responses[connection.fileno()] = response
print(connections)
elif event & select.EPOLLIN:
requests[fileno] += connections[fileno].recv(1024)
event_imp.modify(fileno, select.EPOLLOUT)
print("Get request from %s : %s" % (connection, requests[fileno]))
elif event & select.EPOLLOUT:
sent = connections[fileno].send(responses[fileno])
responses[fileno] = responses[fileno][sent:]
if len(responses[fileno]) == 0:
event_imp.modify(fileno, 0)
connections[fileno].shutdown(socket.SHUT_RDWR)
elif event & select.EPOLLHUP:
event_imp.unregister(fileno)
connections[fileno].close()
del connections[fileno]
finally:
event_imp.unregister(server.fileno())
event_imp.close()
server.close()
可以看到,我们在一开始将监听TCP连接的socket在epoll上注册了EPOLLIN事件,并在新连接可用时为新连接注册了EPOLLIN事件,当新连接的内容接受完毕时,我们将连接注册的事件改为了EPOLLOUT,并在该fd可写时发送了HTTP报文。
这其实就是Tornado IOLoop最简化版的实现。
一个复制集群最多可以有50个成员,但是最多只能有7个可投票成员。
成员数应为奇数,偶数集群应该添加仲裁(Arbiter)节点。
仲裁节点不保存数据,占用资源更少。
| 成员数 | 可进行投票的最小成员数量 | 可容忍错误数 |
|---|---|---|
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
hidden和delayed成员,可实现特殊功能,如备份或者报警。
在3.2之后,mongodb使用protocolVersion:1作为选举协议。
每个成员每两秒会发送一个心跳请求到所有成员,如果10秒内没有回应,会被发送心跳的成员标记为不可达。
就算复制集群已经有主节点后,选举算法也会尽可能的让优先级最高的从节点发起新的选举。
拥有高优先级的从节点相比那些优先级较低的,会更频繁的提出选举请求,并且更有可能被选举为主节点。
低优先级从节点也有可能被选举为主节点,但是高优先级的从节点会很快发出新的请求,从而代替低优先级的节点成为主节点。
当主节点与少数节点被网络隔离时,主节点会主动退位,变为从节点。同时,一个能与大部分节点连接的节点会发起投票从而选出新的主节点。
ProtocolVersion 1中取消了否决票,详见Vetos。
复制集群通过members[n].votes属性与成员状态state来判断一个成员是否可以参与投票。
Vote:3.2:
votes为0,priority为0,priority为0的成员votes不能为0.State:
只有一下状态的成员可以参与投票。
官方建议将节点部署在不同的数据中心,以防止核弹摧毁数据中心。
在监督学习时,我们经常会看到别人把数据分为training set和test set,究竟为何要这样做?
如果你在使用同一组数据来训练模型,并且用同一组数据来测试模型的话,模型会给出一个相当完美的得分。
但是当你将模型扩展到未知数据时,效果就差强人意了。
这种情况叫做过拟合。
为了避免这种情况,我们会将数据分成两部分,一部分用来训练,叫做training set, 另一部分用来测试,叫做test set。
看起来似乎这样就可以解决问题了?
并没有。
每个模型还有一些对应的参数(hyperparameters),当我们在测试集上调参时,我们其实不知不觉中泄露了一些测试集的信息给模型,这样还是会造成模型无法泛化。
为了解决这个问题,我们还需要一部分数据,来做validation set。
于是,整个流程变成了。
分割数据 -> training set训练 -> validation set验证 -> test set验证
但是把原有的数据分成三份,大量的减少了用于训练的数据量。这就使模型的结果过度依赖于用于训练数据。
Cross-validation 就是用来解决这个问题。
引入CV后,测试集仍旧用于最终的评估,但是我们不再需要validation-set。
已k-fold CV为例,训练集被分类k个小数据集,之后用一下的方式训练模型:
0. 初始化一个新模型
1. 用k-1份数据来训练模型。
2. 用剩下的那一份数据来对模型进行验证。
模型的总体表现用k次评估的平均值来表示。
这样可以在保证训练数据量的情况下来保证模型评估的准确性。
在引入CV后,整个流程变为:
分割数据 -> cv训练、评估数据 -> test set最终评估
title: Classic-And-Old-Class
date: 2017-02-24 14:58:57
我比较崇尚新兴的东西,所以一直都在使用Python3,但无奈大部分生产环境都是Python2.x。
旧式类是为了保证向后兼容而在2.1中引进的类。
他通过非继承的直接定义
class OldClass:
pass
或者继承自旧式类来创建
class OldChild(OldMather, OldFather):
pass
新式类通过继承自object或者type
class NewClass(object):
pass
class NewClass2(object):
pass
或者继承自其它新式类创建
class NewChild(NewParent):
pass
关于描述符又是一个内容很多的东西,之后单独开篇讲。
In [13]: class Test:
...: pass
...:
In [14]: class Test1(object):
...: pass
...:
In [15]: t1 = Test()
In [16]: t2 = Test1()
In [17]: t1.__class__
Out[17]: <class __main__.Test at 0x10c314ae0>
In [18]: t2.__class__
Out[18]: __main__.Test1
In [19]: type(t1)
Out[19]: instance
In [20]: type(t2)
Out[20]: __main__.Test1
Classic Class:
In [24]: class Base:
...: def hi(self):
...: print("I am base")
...:
In [25]: class A(Base):
...: pass
...:
In [26]: class B(Base):
...: def hi(self):
...: print("I am B")
...:
In [27]: class C(A,B):
...: pass
...:
In [29]: c = C()
In [30]: c.hi()
I am base
New Class
In [31]: class NewBase:
...: def hi(self):
...: print("I am Base")
...:
In [32]: class NewBase(object):
...: def hi(self):
...: print("I am Base")
...:
In [33]: class NewA(NewBase):
...: pass
...:
In [34]: class NewB(NewBase):
...: def hi(self):
...: print("I am NB")
...:
In [35]: class NewC(NewA, NewB):
...: pass
...:
In [36]: newc = NewC()
In [37]: newc.hi()
I am NB
其中两种类的检索顺序为:
新式类:
先在同层进行检索,再深入进行,比较像BFS。
旧式类: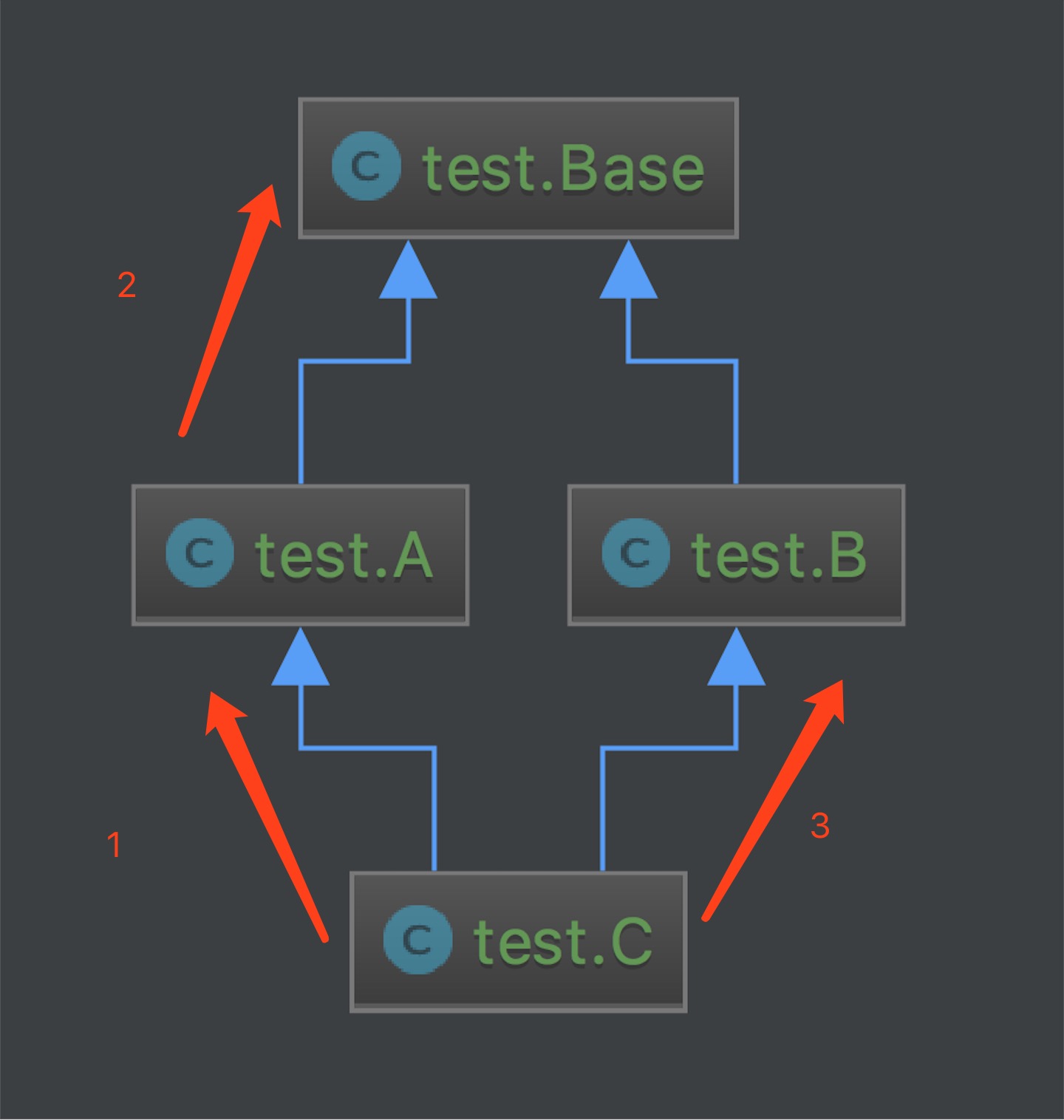
验证继承树向上,DFS。
相比之下, classic class没有任何优势,甚至像__slot__这种Python中的Magic Method都无法使用。旧式类在3.x后被淘汰,大概也是这个原因。
数据驱动
系统诊断
单机容量低
内存
网络
响应慢